
Automattic, virksomheden bag WordPress og Tumblr, er i forhandlinger om at tjene penge på brugerindhold ved at sælge sine data til kunstig intelligens-virksomheder, herunder MidJourney og OpenAI. Disse data fra bloggingplatformene Tumblr og WordPress.com vil blive brugt til at træne AI-modellerne.
Mens detaljerne i transaktionen stadig er uklare, har nyheden rejst bekymringer blandt brugerne om det potentielle misbrug af deres private indhold på de to blogplatforme. 404 Media antyder også, at der opstod interne konflikter i Automattic, fordi det indsamlede indhold omfattede private data, som ikke var beregnet til at blive opbevaret i virksomheden.
Som svar på tilbageslaget er Automattic indstillet til at introducere en ny funktion, der vil give brugerne mulighed for at fravælge deling af deres data til AI-træning. Virksomheden bekræfter i et blogindlæg sin forpligtelse til at give Tumblr- og Wordpress-brugere mere kontrol over deres indhold. Nævner at frigive en indstilling for “at modvirke udforskning af AI-virksomheder”, der forklarer, at førende AI-udforskningsplatforme er blokeret som standard.
Problemet med brugen af indhold fra blogs af virksomheder, der udvikler AI-modeller, er ikke kun begrænset til de platforme, der administreres af virksomheden Automattic. Både OpenAI og Google bruger crawler-bots, der samler oplysninger fra alle websteder for at træne deres AI-modeller. Processen ligner dataindsamling fra søgemaskiner.
Hvordan kan du blokere OpenAI og Gemini (Bard) fra at tage data fra din blog?
Hvis du er ejer af en blog eller et websted, og du ikke ønsker, at dataene fra den skal bruges til at træne OpenAI og Gemini kunstig intelligens-modeller, kan du blokere adgangen for robotter (crawlere) til indholdet. Denne begrænsning kan indstilles via filen robots.txt.
OpenAI Crawlers
User-agent: GPTBot
Disallow: /Gemini Crawlers
User-agent: Google-Extended
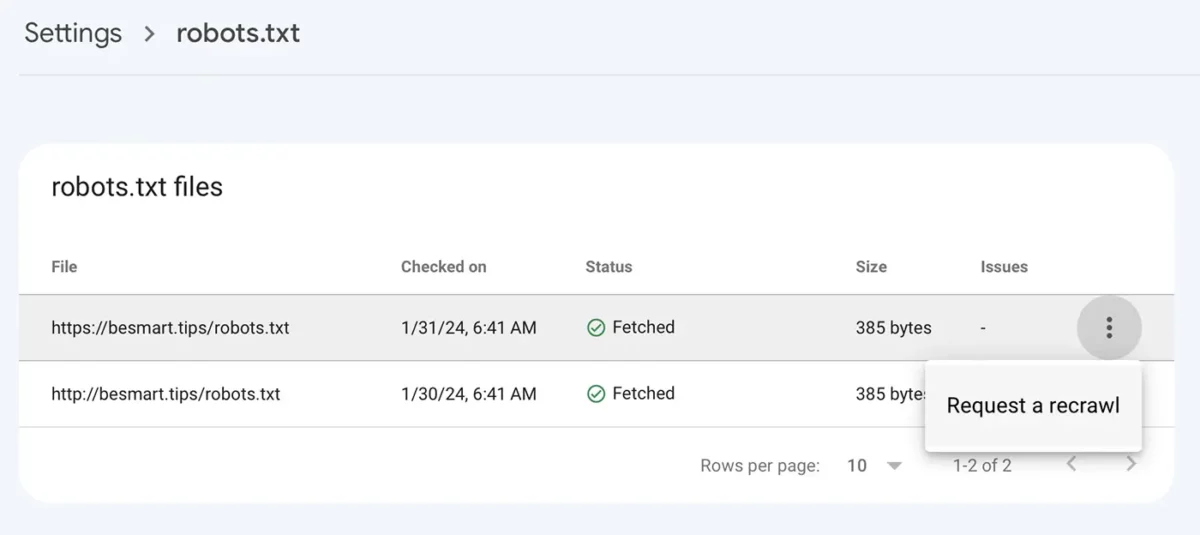
Disallow: /Når du har gemt robots.txt-filen med de nye linjer, skal du gå til Google Console for at: Settings > robots.txt > klik på menuen med de tre prikker, klik “Request a recrawl“.
Relaterede: GPT-5 og den nye Crawler GPTBOT-web udviklet af Openai
For Tumblr- og Wordpress-brugere vil adgangen til datahentning fra blogs af OpenAI eller andre kunstig intelligens-udviklingsvirksomheder kunne blokeres ved hjælp af de værktøjer, der stilles til rådighed af Automattic-virksomheden.
Du kan også være interesseret i...
