
Automattic, la empresa detrás de WordPress y Tumblr, está en conversaciones para monetizar el contenido de los usuarios vendiendo sus datos a empresas de inteligencia artificial, incluidas MidJourney y OpenAI. Estos datos de las plataformas de blogs Tumblr y WordPress.com se utilizarán para entrenar los modelos de IA.
Si bien los detalles de la transacción aún no están claros, la noticia ha generado preocupación entre los usuarios sobre el posible uso indebido de su contenido privado en las dos plataformas de blogs. 404 Media también sugiere que surgieron conflictos internos dentro de Automattic porque el contenido recopilado incluía datos privados que no estaban destinados a ser conservados dentro de la empresa.
En respuesta a la reacción, Automattic está preparado para introducir una nueva función que permitirá a los usuarios optar por no compartir sus datos para el entrenamiento de IA. La compañía, en una publicación de blog, afirma su compromiso de brindar a los usuarios de Tumblr y Wordpress más control sobre su contenido. Menciona la liberación de una configuración para “para desalentar la exploración por parte de empresas de IA”, explicando que las principales plataformas de exploración de IA están bloqueadas de forma predeterminada.
El problema del uso de contenidos de blogs por parte de empresas que desarrollan modelos de IA no se limita únicamente a las plataformas gestionadas por la empresa Automattic. Tanto OpenAI como Google utilizan robots rastreadores que recopilan información de todos los sitios web para entrenar sus modelos de IA. El proceso es similar a la recopilación de datos por parte de los motores de búsqueda.
¿Cómo puedes impedir que OpenAI y Gemini (Bard) tomen datos de tu blog?
Si eres propietario de un blog o sitio web y no quieres que los datos del mismo se utilicen para entrenar los modelos de inteligencia artificial OpenAI y Gemini, puedes bloquear el acceso de robots (rastreadores) al contenido. Esta restricción se puede establecer a través del archivo robots.txt.
OpenAI Crawlers
User-agent: GPTBot
Disallow: /Gemini Crawlers
User-agent: Google-Extended
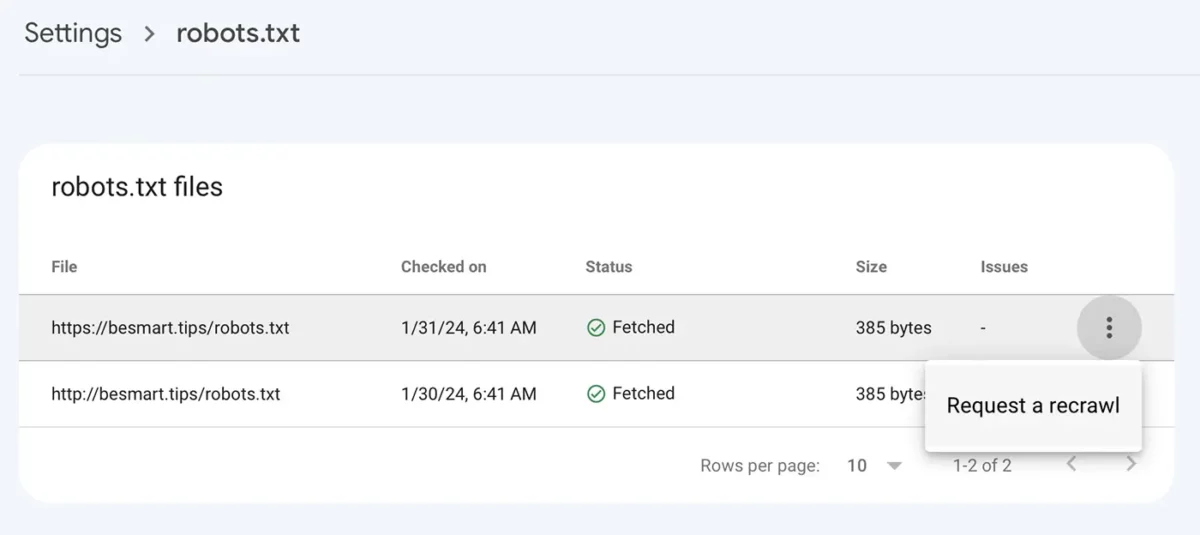
Disallow: /Después de guardar el archivo robots.txt con las nuevas líneas, vaya a Google Console para: Settings > robots.txt > haga clic en el menú con los tres puntos, haga clic en “Request a recrawl“.
Relacionado: GPT-5 y la nueva web Crawler GPTBOT desarrollada por OpenAI
Para los usuarios de Tumblr y Wordpress, el acceso a la recuperación de datos de blogs por parte de OpenAI u otras empresas de desarrollo de inteligencia artificial podrá bloquearse mediante las herramientas puestas a disposición por la empresa Automattic.
También te puede interesar...
