
Automattic, compania din spatele WordPress și Tumblr, are în plan discuții pentru a monetiza conținutul utilizatorilor prin vânzarea datelor sale către companii de inteligență artificială, inclusiv MidJourney și OpenAI. Aceste date de pe platformele de blogging Tumblr si WordPress.com vor fi utilizate pentru antrenarea modelelor AI.
Bien que les détails de la transaction ne soient pas encore clairs, la nouvelle a suscité des inquiétudes parmi les utilisateurs quant à une éventuelle utilisation abusive de leur contenu privé sur les deux plateformes de blogs. 404 Media suggère également que des conflits internes sont survenus au sein d'Automattic parce que le contenu collecté incluait des données privées qui n'étaient pas destinées à être conservées au sein de l'entreprise.
En réponse à cette réaction, Automattic s'apprête à introduire une nouvelle fonctionnalité qui permettra aux utilisateurs de refuser de partager leurs données pour la formation en IA. La société, dans un article de blog, affirme son engagement à donner aux utilisateurs de Tumblr et Wordpress plus de contrôle sur leur contenu. Mentionne la publication d'un paramètre pour “décourager l’exploration par les sociétés d’IA”, expliquant que les principales plateformes d'exploration de l'IA sont bloquées par défaut.
La problématique de l’utilisation des contenus des blogs par les entreprises développant des modèles d’IA ne se limite pas aux seules plateformes gérées par la société Automattic. OpenAI et Google utilisent tous deux des robots d'exploration qui collectent des informations sur tous les sites Web pour entraîner leurs modèles d'IA. Le processus est similaire à la collecte de données par les moteurs de recherche.
Comment pouvez-vous empêcher OpenAI et Gemini (Bard) de récupérer les données de votre blog ?
Si vous êtes propriétaire d'un blog ou d'un site Web et que vous ne souhaitez pas que les données de celui-ci soient utilisées pour entraîner les modèles d'intelligence artificielle OpenAI et Gemini, vous pouvez bloquer l'accès des robots (crawlers) au contenu. Cette restriction peut être définie via le fichier robots.txt.
OpenAI Crawlers
User-agent: GPTBot
Disallow: /Gemini Crawlers
User-agent: Google-Extended
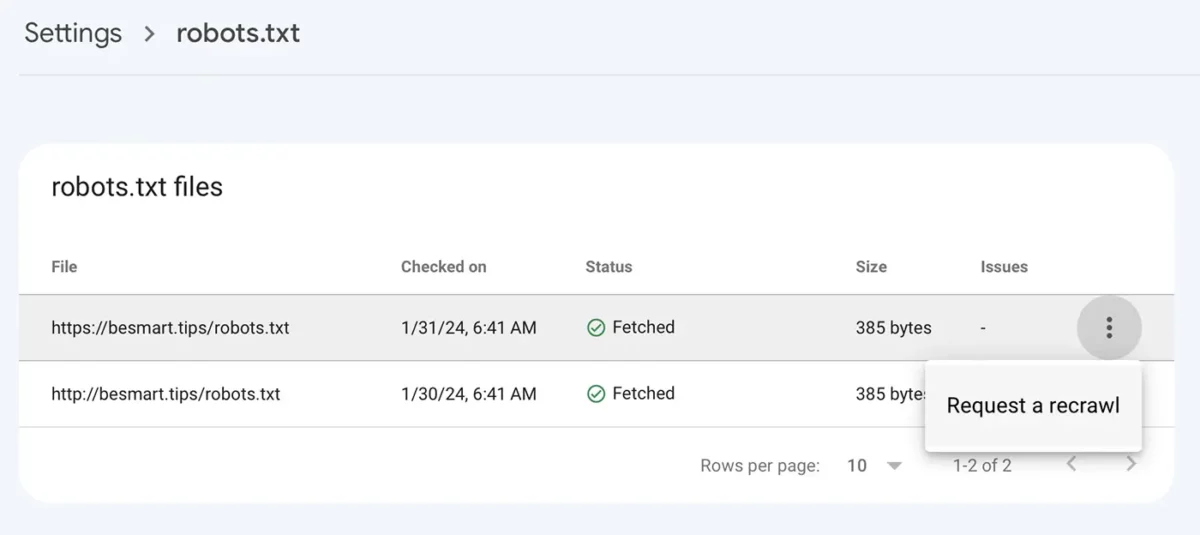
Disallow: /Après avoir enregistré le fichier robots.txt avec les nouvelles lignes, accédez à la console Google pour : Settings > robots.txt > cliquez sur le menu avec les trois points, cliquez “Request a recrawl“.
Liens : GPT-5 et le nouveau Crawler GPTBOT Web développé par OpenAI
Pour les utilisateurs de Tumblr et Wordpress, l'accès aux données de récupération des blogs par OpenAI ou d'autres sociétés de développement d'intelligence artificielle pourra être bloqué grâce aux outils mis à disposition par la société Automattic.
Vous pourriez également être intéressé par...
