
Automattic, compania din spatele WordPress și Tumblr, are în plan discuții pentru a monetiza conținutul utilizatorilor prin vânzarea datelor sale către companii de inteligență artificială, inclusiv MidJourney și OpenAI. Aceste date de pe platformele de blogging Tumblr si WordPress.com vor fi utilizate pentru antrenarea modelelor AI.
Deși detaliile tranzacției sunt încă neclare, această veste a stârnit îngrijorări printre utilizatori cu privire la utilizarea potențială în scopuri necorespunzătoare a conținutului lor privat de pe cele două platforme de blogging. De asemenea, 404 Media sugerează că au apărut conflicte interne în cadrul Automattic, deoarece conținutul colectat include date private care nu erau destinate retenției în cadrul companiei.
În răspuns la reacțiile negative, Automattic urmează să introducă o nouă caracteristică care va permite utilizatorilor să opteze să nu-și partajeze datele pentru antrenarea AI-ului. Compania, într-o postare pe blog, își afirmă angajamentul de a oferi utilizatorilor Tumblr și Wordpress un control mai mare asupra conținutului lor. Menționează lansarea unei setări pentru „a descuraja explorarea de către companiile de AI”, explicând că platformele de explorare AI de vârf sunt blocate în mod implicit.
Problema utilizării conținutului de pe bloguri de către companiile care dezvoltă modele AI, nu se limitează numai la platformele administrate de compania Automattic. Atât OpenAI căt și Google, utilizează roboți de tip crawler prin care culeg informații de pe toate site-urile, pentru a antrena modelele de inteligență artificială. Procesul este similar culegerii de date de către motoarele de căutare.
Cum poți bloca OpenAI și Gemini (Bard) să preia datele de pe blogul tău?
Dacă sunteți posesorului unui blog sau al unui site și nu doriți ca datele de pe acesta să fie utilizate pentru antrenarea modelelor de inteligență artificială OpenAI și Gemini, puteți bloca accesul roboților (crawlers) la conținut. Această restricție se poate pune prin intermediul fișierului robots.txt.
OpenAI Crawlers
User-agent: GPTBot
Disallow: /Gemini Crawlers
User-agent: Google-Extended
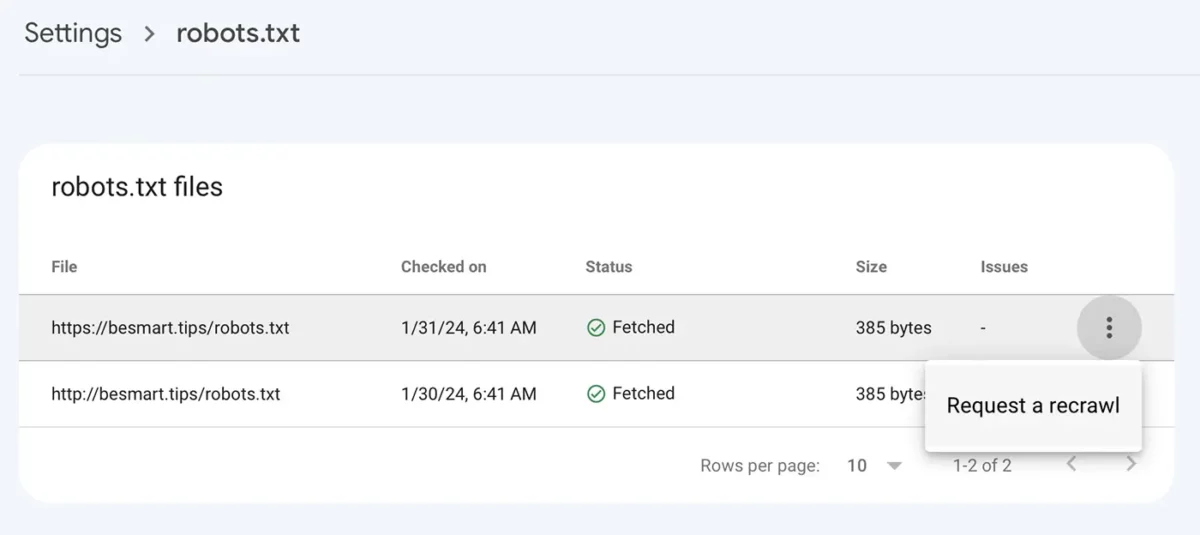
Disallow: /După ce salvați fisierul robots.txt cu noile linii, mergeți în Google Console la: Settings > robots.txt > click pe meniul cu cele trei puncte, click „Request a recrawl„.
Related: GPT-5 și noul web crawler GPTBot dezvoltat de OpenAI
Pentru utilizatorii de Tumblr și Wordpress, accesul preluării datelor de pe bloguri de către OpenAI sau alte companii de dezvoltare a inteligenței artificiale, va putea fi blocat prin intermediul instrumentelor puse la dispoziție de compania Automattic.
Te-ar putea interesa și...
