
Automattic, företaget bakom WordPress och Tumblr, är i samtal för att tjäna pengar på användarinnehåll genom att sälja sin data till företag med artificiell intelligens inklusive MidJourney och OpenAI. Denna data från bloggplattformarna Tumblr och WordPress.com kommer att användas för att träna AI-modellerna.
Även om detaljerna i transaktionen fortfarande är oklara, har nyheten väckt oro bland användare om potentiellt missbruk av deras privata innehåll på de två bloggplattformarna. 404 Media menar också att interna konflikter uppstod inom Automattic eftersom innehållet som samlades in innefattade privata uppgifter som inte var avsedda att behållas inom företaget.
Som svar på motreaktionen kommer Automattic att introducera en ny funktion som gör det möjligt för användare att välja bort att dela sin data för AI-träning. Företaget bekräftar i ett blogginlägg sitt åtagande att ge Tumblr- och Wordpress-användare mer kontroll över sitt innehåll. Nämner att släppa en inställning för “för att motverka utforskning av AI-företag”, som förklarar att ledande AI-utforskningsplattformar är blockerade som standard.
Problemet med användningen av innehåll från bloggar av företag som utvecklar AI-modeller är inte bara begränsat till de plattformar som hanteras av företaget Automattic. Både OpenAI och Google använder sökrobotar som samlar information från alla webbplatser för att träna sina AI-modeller. Processen liknar datainsamling av sökmotorer.
Hur kan du blockera OpenAI och Gemini (Bard) från att ta data från din blogg?
Om du är ägare till en blogg eller webbplats och du inte vill att data från den ska användas för att träna OpenAI- och Gemini-modellerna för artificiell intelligens, kan du blockera åtkomsten av robotar (crawlers) till innehållet. Denna begränsning kan ställas in via filen robots.txt.
OpenAI Crawlers
User-agent: GPTBot
Disallow: /Gemini Crawlers
User-agent: Google-Extended
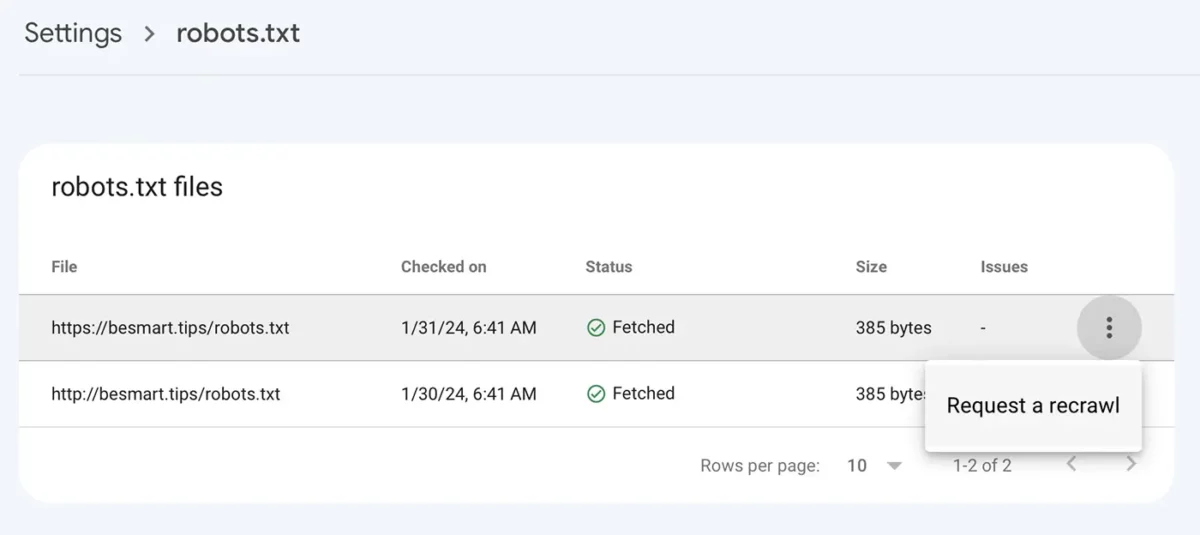
Disallow: /När du har sparat robots.txt-filen med de nya raderna går du till Google Console för att: Settings > robots.txt > klicka på menyn med de tre prickarna, klicka “Request a recrawl“.
Släkt: GPT-5 och den nya Crawler GPTBOT-webben utvecklad av OpenAI
För Tumblr- och Wordpress-användare kommer åtkomsten av datahämtning från bloggar av OpenAI eller andra företag för utveckling av artificiell intelligens att kunna blockeras med hjälp av de verktyg som gjorts tillgängliga av Automattic-företaget.
Du kanske också är intresserad av...
