
La mayoría de las veces, cuando necesite bloquear el acceso SeekportBot o para otros crawl bots En un sitio web, las razones son simples. La araña web tiene demasiados acceso en un corto período de tiempo y solicita los recursos web del servidor, o proviene de un motor de búsqueda en el que no desea que su sitio web se indexe.
contenido
Es muy beneficioso que un sitio web haya visitado por Bots Crawl. Estas especies web están diseñadas para explorar, procesar e indexar el contenido de las páginas web en los motores de búsqueda. Google y Bing usan tales bots de rastreo. Pero también hay motores de búsqueda que usan robots para recopilar datos de las páginas web. Seekport Es uno de estos motores de búsqueda, que utiliza el Crawler de SeekPortbot para indexar páginas web. Desafortunadamente, a veces lo usa de manera excesiva y hace un tráfico inútil.
¿Qué es el Seekportbot?
SeekportBot Es un web crawler desarrollado por la empresa Seekport, que tiene su sede en Alemania (pero usa IP de varios países, incluida Finlandia). Este bot se utiliza para explorar e indexar sitios web para que puedan mostrarse en los resultados de búsqueda en el motor de búsqueda Seekport. Un motor de búsqueda no funcional, hasta donde yo creo. Al menos, no devolví resultados para ninguna frase clave.
SeekportBot USAR user agent:
"Mozilla/5.0 (compatible; SeekportBot; +https://bot.seekport.com)"¿Cómo se bloquea el acceso de SeekPortbot u otros bots de rastreo a un sitio web?
Si ha llegado a la conclusión de que esta web de araña u otra, no es necesario escanear todo su sitio web y hacer un tráfico inútil por el servidor web, tiene varias formas de bloquear su acceso.
Firewall la nivel de server web
Se aplica el firewall open-source que se puede instalar en sistemas operativos Linux y se puede configurar para bloquear el tráfico en varios criterios. Dirección IP, ubicación, puertos, protocolos o agente de usuario.
APF (Advanced Policy Firewall) Es un software a través del cual puede bloquear los golpes no deseados, a nivel de servidor.
Debido a que SeekPortbot y otras arañas web usan varios bloques IP, la regla de bloqueo más eficiente se basa en “user agent“. Asar, si quieres bloquear el acceso SeekportBot con la ayuda APF, todo lo que tiene que hacer es conectarse al servidor web por SSH, y agregue la regla de filtrado al archivo de configuración.
1. Abra el archivo de configuración con nano (u otro editor).
sudo nano /etc/apf/conf.apf2. Busque la línea que comience con “IG_TCP_CPORTS” Y agregue el agente de usuario que desea bloquear al final de esta línea, seguido de una coma. Por ejemplo, si quieres bloquear user agent “SeekportBot“, la línea debería verse así:
IG_TCP_CPORTS="80,443,22" && IG_TCP_CPORTS="$IG_TCP_CPORTS,SeekportBot"3. Guarde el archivo y reinicie el servicio APF.
sudo systemctl restart apf.serviceacceso “Seekportbot” será bloqueado.
Filtración web crawls con la ayuda de Cloudflare – Bloquee su acceso de Seekportbot
Con la ayuda de CloudFre, me parece el método más seguro y práctico por el cual puede limitar de varias maneras el acceso a algunos bits a un sitio web. El método que he utilizado en el caso de SeekportBot para filtrar el tráfico a una tienda en línea.
Suponiendo que ya tenga el sitio web agregado a CloudFlore y los servicios DNS se activan (es decir, el tráfico al sitio es realizado por Cloud), siga los pasos a continuación:
1. Abra la cuenta de Clouflare y vaya al sitio web para el cual desea limitar el acceso.
2. Ve a: Security → WAF y agregar una nueva regla. Create rule.
3. Alegi un nume pentru noua regula, Field: User Agent – Operator: Contains – Value: SeekportBot (u otro nombre de bot) – Choose action: Block – Deploy.
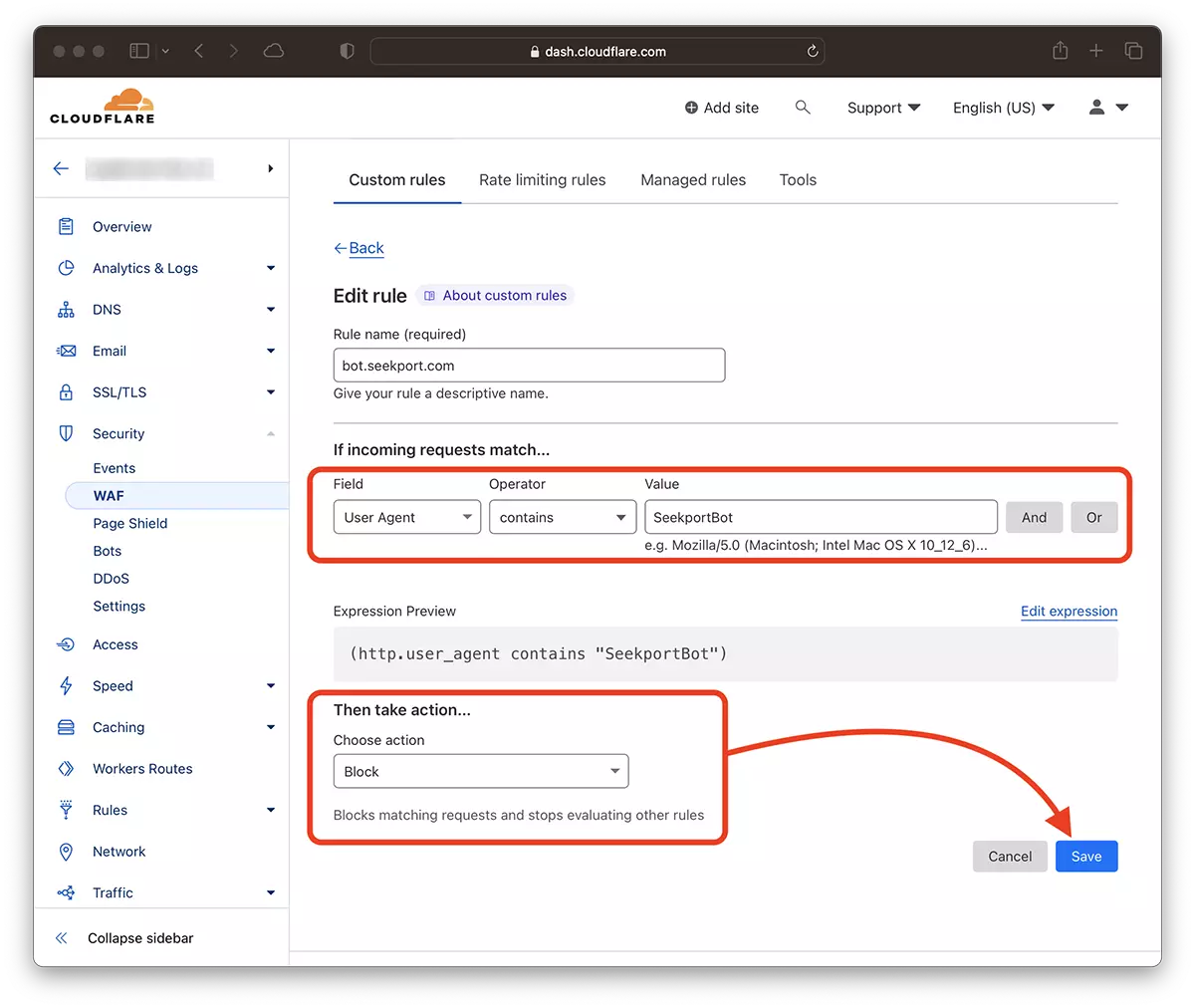
En solo unos segundos la nueva regla WAF (Web Application Firewall) Comienza a tener su efecto.
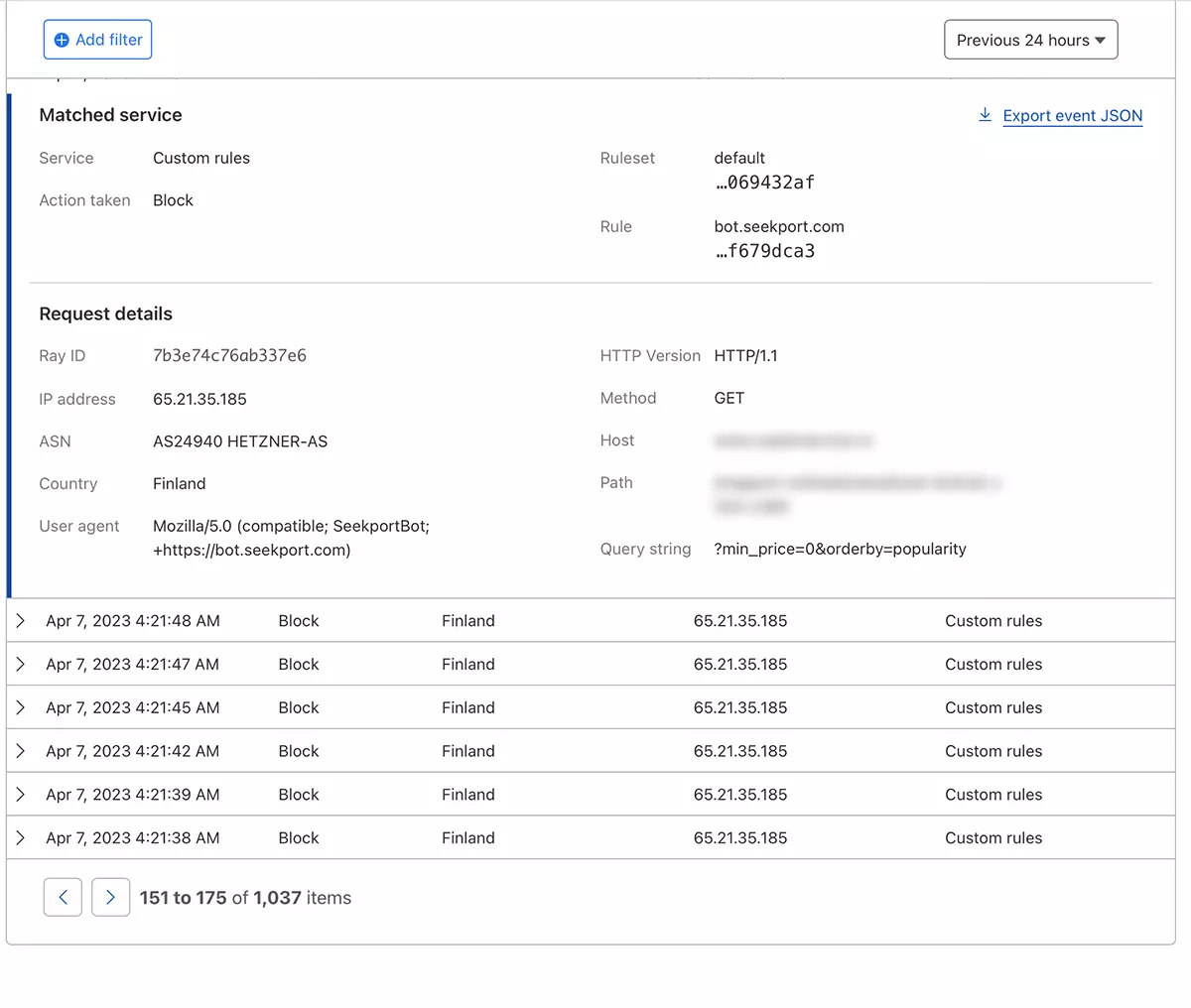
En teoría, la frecuencia por la cual se puede establecer una red araña para acceder a un sitio desde robots.txt, aunque… Es solo en teoría.
User-agent: SeekportBot
Crawl-delay: 4Muchos rastreadores web (aparte de Bing y Google) no siguen estas reglas.
En conclusión, si identifica una red de rastreo que accede excesivamente a su sitio, es mejor bloquear su acceso total. Por supuesto, si este bot no es de un motor de búsqueda donde está interesado en estar presente.
También te puede interesar...
