
Most of the time, when you need to block access SeekportBot or to others crawl bots At a website, the reasons are simple. The web spider makes too many access in a short period of time and requests the server web resources, or comes from a search engine in which you do not want your website to be indexed.
content
It is very beneficial for a website has visited by Crawl Bots. These web spides are designed to explore, process and index the content of the web pages in search engines. Google and bing use such Crawl Bots. But there are also search engines that use robots for collecting data from web pages. Seekport It is one of these search engines, which uses the SeekportBot crawler to index web pages. Unfortunately, it sometimes uses it in an excessive way and does useless traffic.
What is the seekportbot?
SeekportBot It's a web crawler developed by the company Seekport, which is based in Germany (but uses IPs from several countries, including Finland). This bot is used to explore and index websites so that they can be displayed in search results on the search engine Seekport. A non -functional search engine, as far as I realize. At least, I did not return results for any key phrase.
SeekportBot USE user agent:
"Mozilla/5.0 (compatible; SeekportBot; +https://bot.seekport.com)"How do you block the access of SeekportBot or other crawl bots to a website
If you have come to the conclusion that this spider web or another, it is not necessary to scan your entire website and make a useless traffic by the web server, you have several ways to block their access.
Firewall the Server Web level
Are the firewall applies open-source which can be installed on Linux operating systems and can be configured to block traffic on several criteria. IP address, location, ports, protocols or user agent.
APF (Advanced Policy Firewall) It is such a software through which you can block unwanted bumps, at the server level.
Because SeekportBot and other web spiders use several IP blocks, the most efficient locking rule is based on “user agent“. Asar, if you want to block access SeekportBot with the help APF, all you have to do is connect to the web server by SSH, and add the filtering rule to the configuration file.
1. Open the configuration file with nano (or other editor).
sudo nano /etc/apf/conf.apf2. Look for the line that starts with “IG_TCP_CPORTS” And add the user agent you want to block at the end of this line, followed by a comma. For example, if you want to block user agent “SeekportBot“, line should look like this:
IG_TCP_CPORTS="80,443,22" && IG_TCP_CPORTS="$IG_TCP_CPORTS,SeekportBot"3. Save the file and restart the APF service.
sudo systemctl restart apf.serviceaccess “SeekportBot” will be blocked.
Filtration web crawls with the help of Cloudflare – Block your SeekportBot access
With the help of Cloudfre it seems to me the safest and most handy method by which you can limit in various ways access to some bits to a website. The method I have used in the case of SeekportBot to filter traffic to an online store.
Assuming you already have the website added to the cloudflore and the DNS services are activated (ie the traffic to the site is done by cloud), follow the steps below:
1. Open the Clouflare account and go to the website for which you want to limit access.
2. Go to: Security → WAF and add a new rule. Create rule.
3. Choose a name for the new rule, Field: User Agent – Operator: Contains – Value: SeekportBot (or other bot name) – Choose action: Block – Deploy.
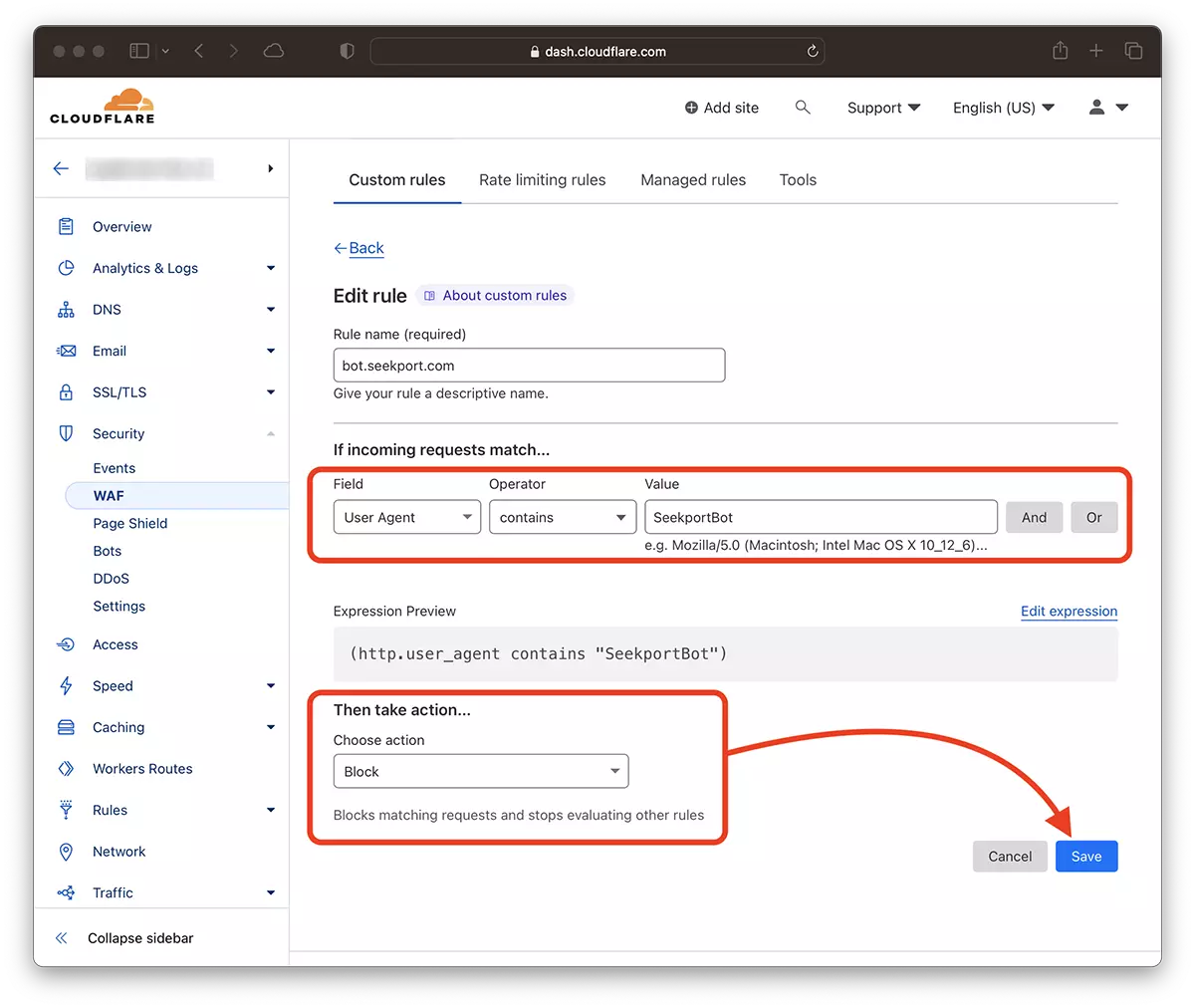
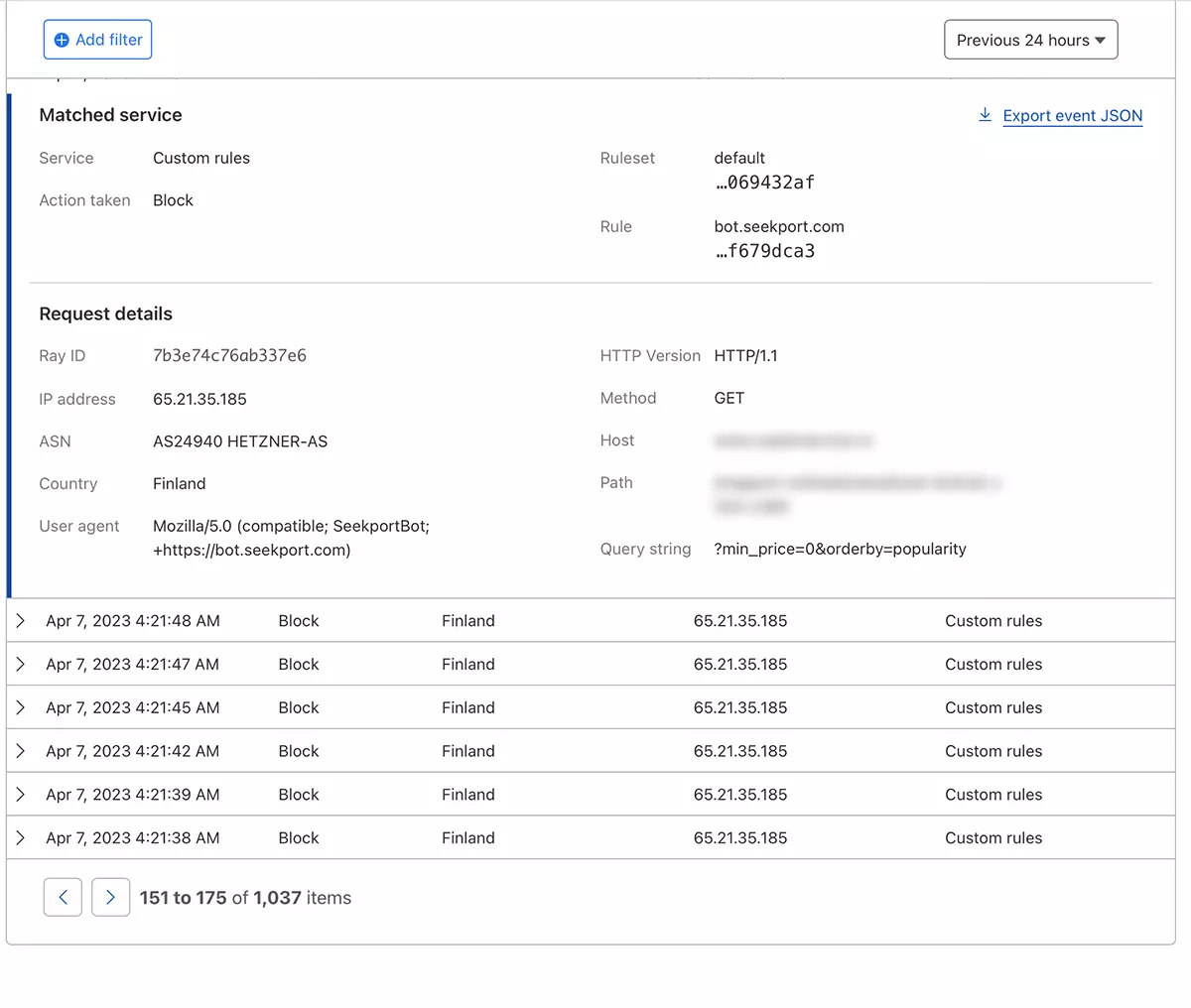
In just a few seconds the new rule WAF (Web Application Firewall) He begins to make his effect.
In theory, the frequency by which a spider web to access a site can be set from robots.txt, though… It's only in theory.
User-agent: SeekportBot
Crawl-delay: 4Many web crawlers (apart from Bing and Google) do not follow these rules.
In conclusion, if you identify a Crawl web that excessively access your site, it is best to block its total access. Of course, if this bot is not from a search engine where you are interested in being present.
You may also be interested in...
