
La plupart du temps, lorsque vous devez bloquer l'accès SeekportBot ou à d'autres crawl bots Sur un site Web, les raisons sont simples. Le Web Spider fait trop d'accès dans un court laps de temps et nécessite les ressources Web du serveur, ou provient d'un moteur de recherche dans lequel vous ne souhaitez pas que votre site Web soit indexé.
contenu
Il est très bénéfique pour un site Web visité par Crawl Bots. Ces spires Web sont conçus pour explorer, traiter et indexer le contenu des pages Web dans les moteurs de recherche. Google et Bing utilisent de tels robots d'exploration. Mais il existe également des moteurs de recherche qui utilisent des robots pour collecter des données à partir des pages Web. Seekport Il s'agit de l'un de ces moteurs de recherche, qui utilise le Crawler Seekportbot pour indexer les pages Web. Malheureusement, il l'utilise parfois de manière excessive et fait du trafic inutile.
Qu'est-ce que le Seekportbot?
SeekportBot C'est un web crawler développé par l'entreprise Seekport, qui est basé en Allemagne (mais utilise des IP de plusieurs pays, dont la Finlande). Ce bot est utilisé pour explorer et indexer des sites Web afin qu'ils puissent être affichés dans les résultats de recherche sur le moteur de recherche Seekport. Un moteur de recherche non fonctionnel, pour autant que je sache. Au moins, je n'ai pas rendu les résultats pour aucune phrase clé.
SeekportBot UTILISER user agent:
"Mozilla/5.0 (compatible; SeekportBot; +https://bot.seekport.com)"Comment bloquez-vous l'accès de Seekportbot ou d'autres robots d'exploitation à un site Web
Si vous êtes arrivé à la conclusion que ce Web Spider ou un autre, il n'est pas nécessaire de scanner l'intégralité de votre site Web et de faire un trafic inutile par le serveur Web, vous avez plusieurs façons de bloquer leur accès.
Pare-feu Le niveau Web du serveur
Le pare-feu s'applique-t-il open-source qui peut être installé sur les systèmes d'exploitation Linux et peut être configuré pour bloquer le trafic sur plusieurs critères. Adresse IP, emplacement, ports, protocoles ou agent utilisateur.
APF (Advanced Policy Firewall) Il s'agit d'un tel logiciel à travers lequel vous pouvez bloquer les bosses indésirables, au niveau du serveur.
Parce que Seekportbot et d'autres araignées Web utilisent plusieurs blocs IP, la règle de verrouillage la plus efficace est basée sur “user agent“. Asar, si vous souhaitez bloquer l'accès SeekportBot avec l'aide APF, tout ce que vous avez à faire est de vous connecter au serveur Web par SSH, et ajoutez la règle de filtrage au fichier de configuration.
1. Ouvrez le fichier de configuration avec nano (ou autre éditeur).
sudo nano /etc/apf/conf.apf2. Recherchez la ligne qui commence par “IG_TCP_CPORTS” Et ajouter l'agent utilisateur que vous souhaitez bloquer à la fin de cette ligne, suivi d'une virgule. Par exemple, si vous voulez bloquer user agent “SeekportBot“, la ligne devrait ressembler à ceci:
IG_TCP_CPORTS="80,443,22" && IG_TCP_CPORTS="$IG_TCP_CPORTS,SeekportBot"3. Enregistrez le fichier et redémarrez le service APF.
sudo systemctl restart apf.serviceaccéder “Seekportbot” sera bloqué.
Filtration web crawls Avec l'aide de Cloudflare – Bloquez votre accès Seekportbot
Avec l'aide de CloudFre, il me semble la méthode la plus sûre et la plus pratique par laquelle vous pouvez limiter de diverses manières l'accès à certains bits à un site Web. La méthode que j'ai utilisée dans le cas de SeekportBot pour filtrer le trafic vers une boutique en ligne.
En supposant que vous avez déjà ajouté le site Web au cloudflore et que les services DNS sont activés (c'est-à-dire que le trafic vers le site est effectué par cloud), suivez les étapes ci-dessous:
1. Ouvrez le compte Clouflare et accédez au site Web pour lequel vous souhaitez limiter l'accès.
2. Allez à: Security → WAF et ajouter une nouvelle règle. Create rule.
3. Choisissez un nom pour la nouvelle règle, Field: User Agent – Operator: Contains – Value: SeekportBot (ou autre nom de bot) – Choose action: Block – Deploy.
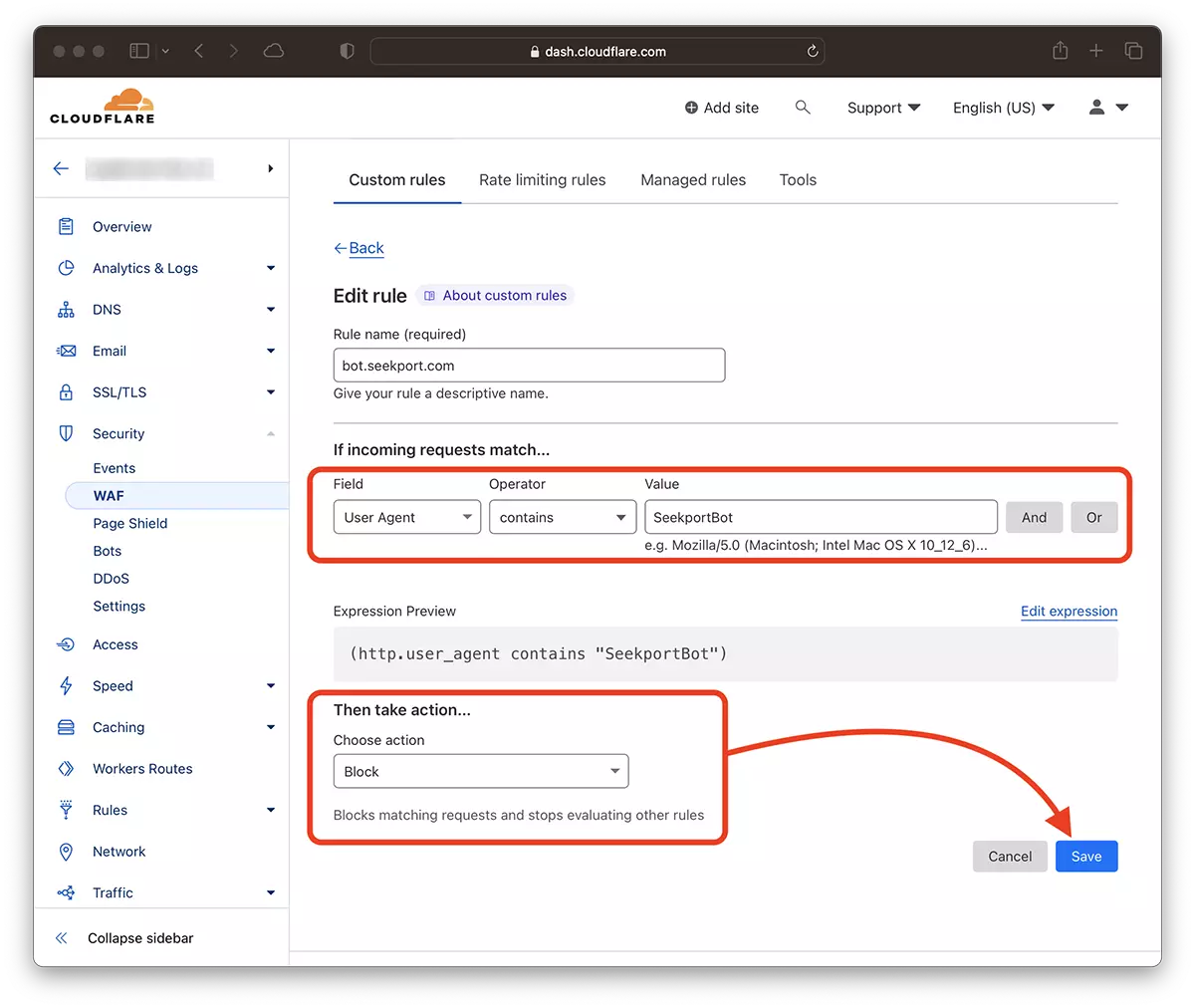
En quelques secondes, la nouvelle règle WAF (Web Application Firewall) Il commence à faire son effet.
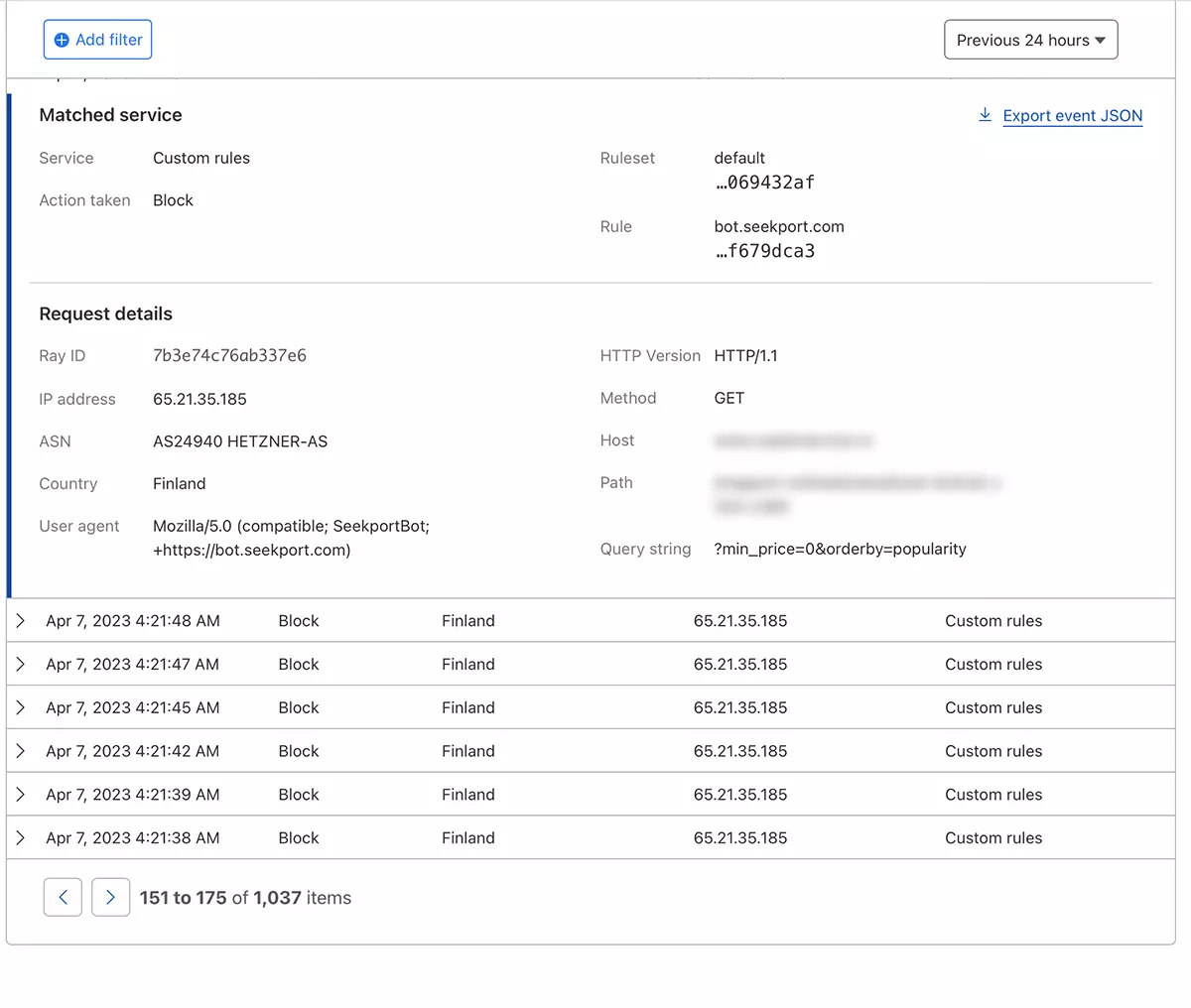
En théorie, la fréquence par laquelle une toile d'araignée pour accéder à un site peut être définie à partir de robots.txt, cependant… Ce n'est qu'en théorie.
User-agent: SeekportBot
Crawl-delay: 4De nombreux robots Web (en dehors de Bing et Google) ne suivent pas ces règles.
En conclusion, si vous identifiez un web d'exploration qui accéde excessivement à votre site, il est préférable de bloquer son accès total. Bien sûr, si ce bot ne vient pas d'un moteur de recherche où vous êtes intéressé à être présent.
Vous pourriez également être intéressé par...
