
ほとんどの場合、アクセスをブロックする必要があるとき SeekportBot または他の人に crawl bots ウェブサイトでは、理由は簡単です。 Web Spiderは、短期間でアクセスが多すぎて、サーバーWebリソースを要求するか、Webサイトをインデックスを作成したくない検索エンジンから提供されます。
コンテンツ
クロールボットが訪れたウェブサイトにとって非常に有益です。これらのWebスパイドは、検索エンジンのWebページのコンテンツを探索、処理、インデックスを作成するように設計されています。 GoogleとBingはそのようなクロールボットを使用します。ただし、Webページからデータを収集するためにロボットを使用する検索エンジンもあります。 Seekport これらの検索エンジンの1つであり、SeekPortbot Crawlerを使用してWebページをインデックス化します。残念ながら、それは時々それを過度の方法で使用し、役に立たないトラフィックをします。
SeekPortbotとは何ですか?
SeekportBot それはです web crawler 会社によって開発されました Seekport、ドイツに拠点を置く(ただし、フィンランドを含むいくつかの国のIPを使用しています)。このボットは、検索エンジンの検索結果に表示できるように、Webサイトを探索およびインデックス作成するために使用されます。 Seekport。私が知る限り、非機能的な検索エンジン。少なくとも、キーフレーズの結果を返しませんでした。
SeekportBot 使用 user agent:
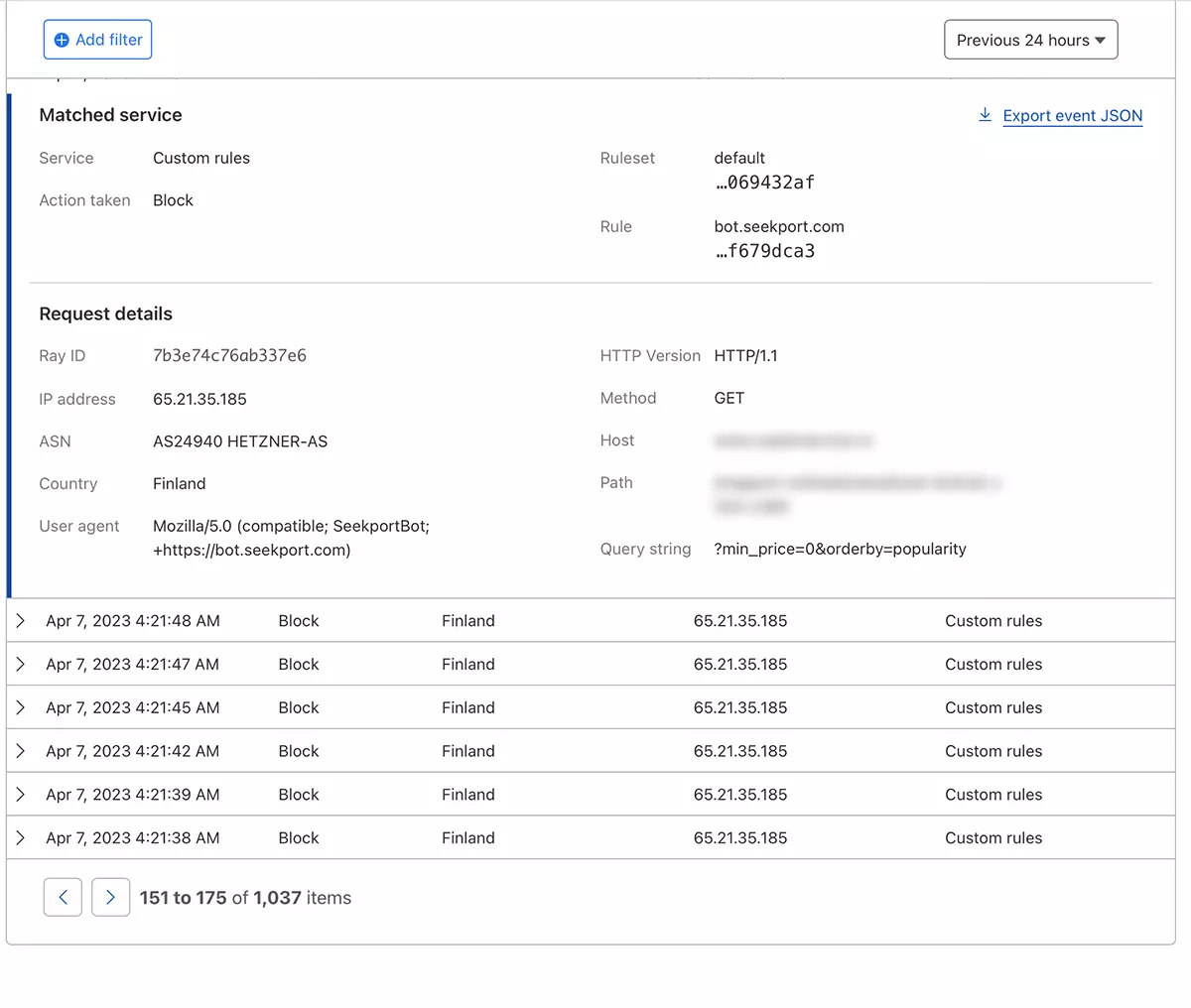
"Mozilla/5.0 (compatible; SeekportBot; +https://bot.seekport.com)"SeekPortbotまたはその他のクロールボットのアクセスをWebサイトにどのようにブロックしますか
このSpider Webまたは別のWebが、Webサイト全体をスキャンしてWebサーバーで役に立たないトラフィックを作成する必要がないという結論に達した場合、アクセスをブロックする方法がいくつかあります。
ファイアウォールサーバーWebレベル
ファイアウォールが適用されますか open-source Linuxオペレーティングシステムにインストールでき、いくつかの基準でトラフィックをブロックするように構成できます。 IPアドレス、場所、ポート、プロトコル、またはユーザーエージェント。
APF (Advanced Policy Firewall) サーバーレベルで、不要なバンプをブロックできるようなソフトウェアです。
SeekPortbotやその他のWebクモはいくつかのIPブロックを使用しているため、最も効率的なロックルールはに基づいています “user agent“。 ASAR、アクセスをブロックする場合 SeekportBot 助けを借りて APF、あなたがしなければならないのは、 SSH、そして、フィルタリングルールを構成ファイルに追加します。
1.構成ファイルをで開きます nano (または他のエディター)。
sudo nano /etc/apf/conf.apf2。始まる行を探します “IG_TCP_CPORTS” このラインの最後にブロックするユーザーエージェントを追加し、その後にコンマを追加します。たとえば、ブロックしたい場合 user agent “SeekportBot“、ラインは次のようになるはずです:
IG_TCP_CPORTS="80,443,22" && IG_TCP_CPORTS="$IG_TCP_CPORTS,SeekportBot"3.ファイルを保存して、APFサービスを再起動します。
sudo systemctl restart apf.serviceアクセス “SeekPortbot” ブロックされます。
濾過 web crawls CloudFlareの助けを借りて – SeekPortBotアクセスをブロックします
CloudFreの助けを借りて、私にとっては、Webサイトへのいくつかのビットへのアクセスをさまざまな方法で制限できる最も安全で最も便利な方法のようです。の場合に使用した方法 SeekportBot オンラインストアへのトラフィックをフィルタリングします。
cloudfloreにウェブサイトを既に追加しており、DNSサービスがアクティブになっていると仮定します(つまり、サイトへのトラフィックはクラウドによって行われます)。以下の手順に従ってください。
1. Clouflareアカウントを開き、アクセスを制限するWebサイトにアクセスします。
2。移動: Security → WAF 新しいルールを追加します。 Create rule。
3. 新しいルールの名前を選択します。 Field: User Agent – Operator: Contains – Value: SeekportBot (または他のボット名) – Choose action: Block – Deploy。
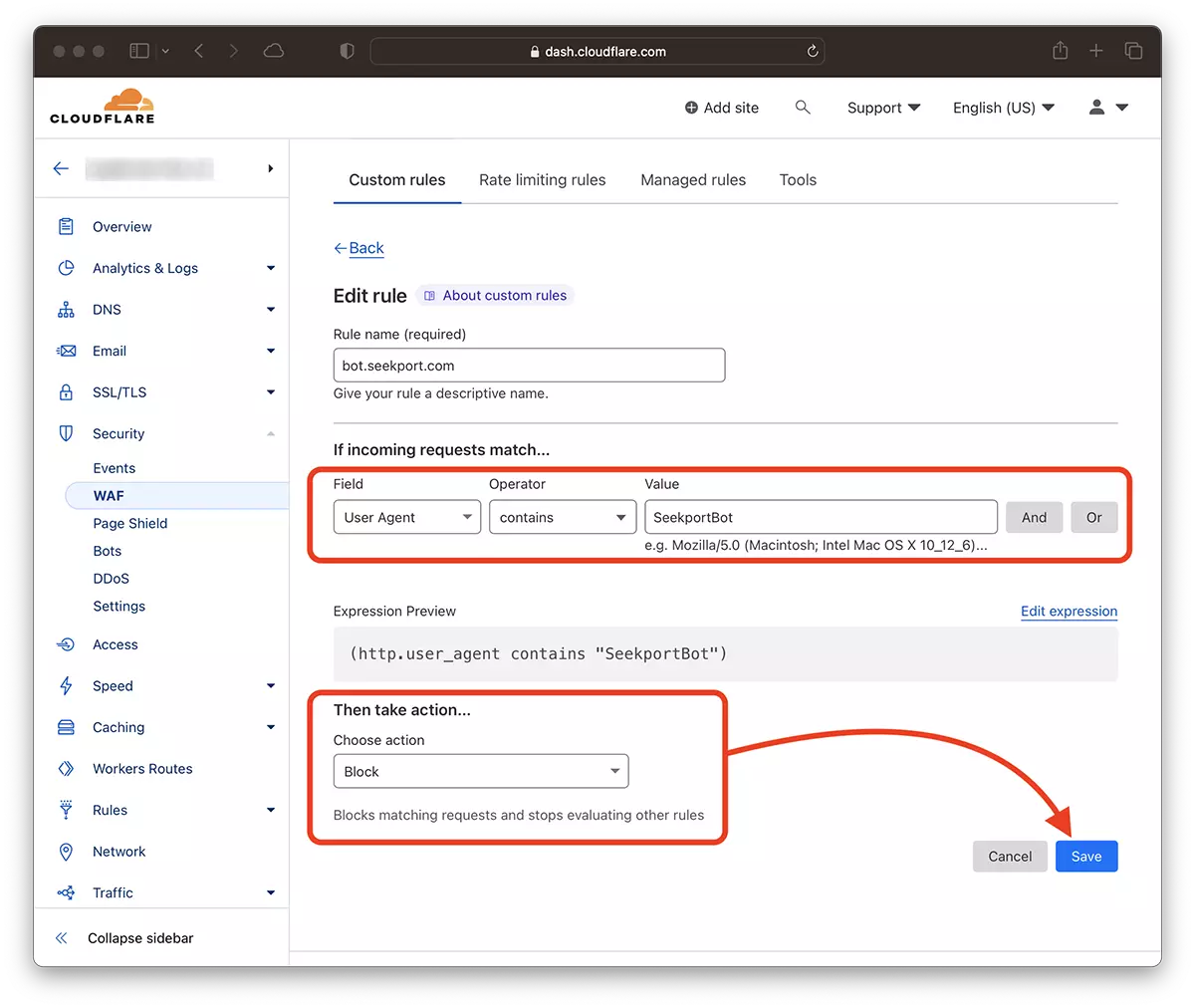
ほんの数秒で新しいルール WAF (Web Application Firewall) 彼は彼の効果を作り始めます。
理論的には、サイトにアクセスするクモのWebがから設定できる頻度 robots.txt、 けれど… それは理論のみです。
User-agent: SeekportBot
Crawl-delay: 4多くのWebクローラー(BingとGoogleを除く)は、これらのルールに従いません。
結論として、サイトに過度にアクセスするクロールWebを特定する場合、その総アクセスをブロックすることが最善です。もちろん、このボットがあなたが存在することに興味がある検索エンジンからのものではない場合。
あなたも興味があるかもしれません...
