
Przez większość czasu musisz zablokować dostęp SeekportBot lub innym crawl bots Na stronie internetowej przyczyny są proste. Spider Web ma zbyt wiele dostępu w krótkim czasie i żąda zasobów internetowych serwera lub pochodzi z wyszukiwarki, w której nie chcesz, aby Twoja witryna była indeksowana.
treść
Jest to bardzo korzystne dla strony internetowej, które odwiedzono przez botki Crawl. Te pająki internetowe zostały zaprojektowane do eksploracji, przetwarzania i indeksowania treści stron internetowych w wyszukiwarkach. Google i Bing używają takich botów. Istnieją jednak wyszukiwarki, które używają robotów do gromadzenia danych ze stron internetowych. Seekport Jest to jedna z tych wyszukiwarek, która korzysta z The Seekportbot Crawler do indeksowania stron internetowych. Niestety czasami używa go w nadmierny sposób i wykonuje bezużyteczny ruch.
Co to jest Seekportbot?
SeekportBot To jest web crawler opracowany przez firmę Seekport, który ma siedzibę w Niemczech (ale wykorzystuje IPS z kilku krajów, w tym Finlandii). Ten bot służy do eksploracji i indeksowania stron internetowych, aby można je było wyświetlić w wynikach wyszukiwania w wyszukiwarce Seekport. O ile zdaję sobie sprawę, że niefunkcjonalna wyszukiwarka. Przynajmniej nie zwróciłem wyników dla żadnego kluczowego wyrażenia.
SeekportBot UŻYWAĆ user agent:
"Mozilla/5.0 (compatible; SeekportBot; +https://bot.seekport.com)"Jak blokować dostęp do Seekportbot lub innych botów pełzających na stronie internetowej
Jeśli doszedłeś do wniosku, że ta sieć pająka lub inna, nie jest konieczne skanowanie całej witryny i wykonanie bezużytecznego ruchu przez serwer WWW, masz kilka sposobów blokowania ich dostępu.
Firewall poziom sieciowy
Czy obowiązuje zapora ogniowa open-source które można zainstalować w systemach operacyjnych Linux i mogą być skonfigurowane tak, aby blokować ruch zgodnie z kilkoma kryteriami. Adres IP, lokalizacja, porty, protokoły lub agent użytkownika.
APF (Advanced Policy Firewall) Jest to takie oprogramowanie, za pomocą którego można blokować niechciane nierówności na poziomie serwera.
Ponieważ Seekportbot i inne pająki internetowe używają kilku bloków IP, najskuteczniejsza reguła blokowania opiera się “user agent“. ASAR, jeśli chcesz zablokować dostęp SeekportBot z pomocą APF, wszystko, co musisz zrobić, to połączyć się z serwerem WWW według SSHi dodaj regułę filtrowania do pliku konfiguracyjnego.
1. Otwórz plik konfiguracyjny za pomocą nano (lub inny redaktor).
sudo nano /etc/apf/conf.apf2. Poszukaj linii, która zaczyna się od “IG_TCP_CPORTS” I dodaj agenta użytkownika, który chcesz zablokować na końcu tego wiersza, a następnie przecinek. Na przykład, jeśli chcesz zablokować user agent “SeekportBot“, linia powinna wyglądać tak:
IG_TCP_CPORTS="80,443,22" && IG_TCP_CPORTS="$IG_TCP_CPORTS,SeekportBot"3. Zapisz plik i uruchom ponownie usługę APF.
sudo systemctl restart apf.servicedostęp “Seekportbot” zostanie zablokowany.
Filtrowanie web crawls z pomocą Cloudflare – Zablokuj swój dostęp do Seekportbot
Z pomocą CloudFre wydaje mi się najbezpieczniejszą i najbardziej poręczną metodą, dzięki której możesz na różne sposoby ograniczyć dostęp do niektórych bitów do strony internetowej. Metoda, którą użyłem w przypadku SeekportBot Aby filtrować ruch do sklepu internetowego.
Zakładając, że masz już dodanie witryny do Cloudflore, a usługi DNS są aktywowane (tj. Ruch do Witryny jest wykonywany przez Cloud), wykonaj poniższe czynności:
1. Otwórz konto Clouflare i przejdź do strony internetowej, dla której chcesz ograniczyć dostęp.
2. Idź do: Security → WAF i dodaj nową zasadę. Create rule.
3. Wybierz nazwę nowej reguły, Field: User Agent – Operator: Contains – Value: SeekportBot (lub inna nazwa bota) – Choose action: Block – Deploy.
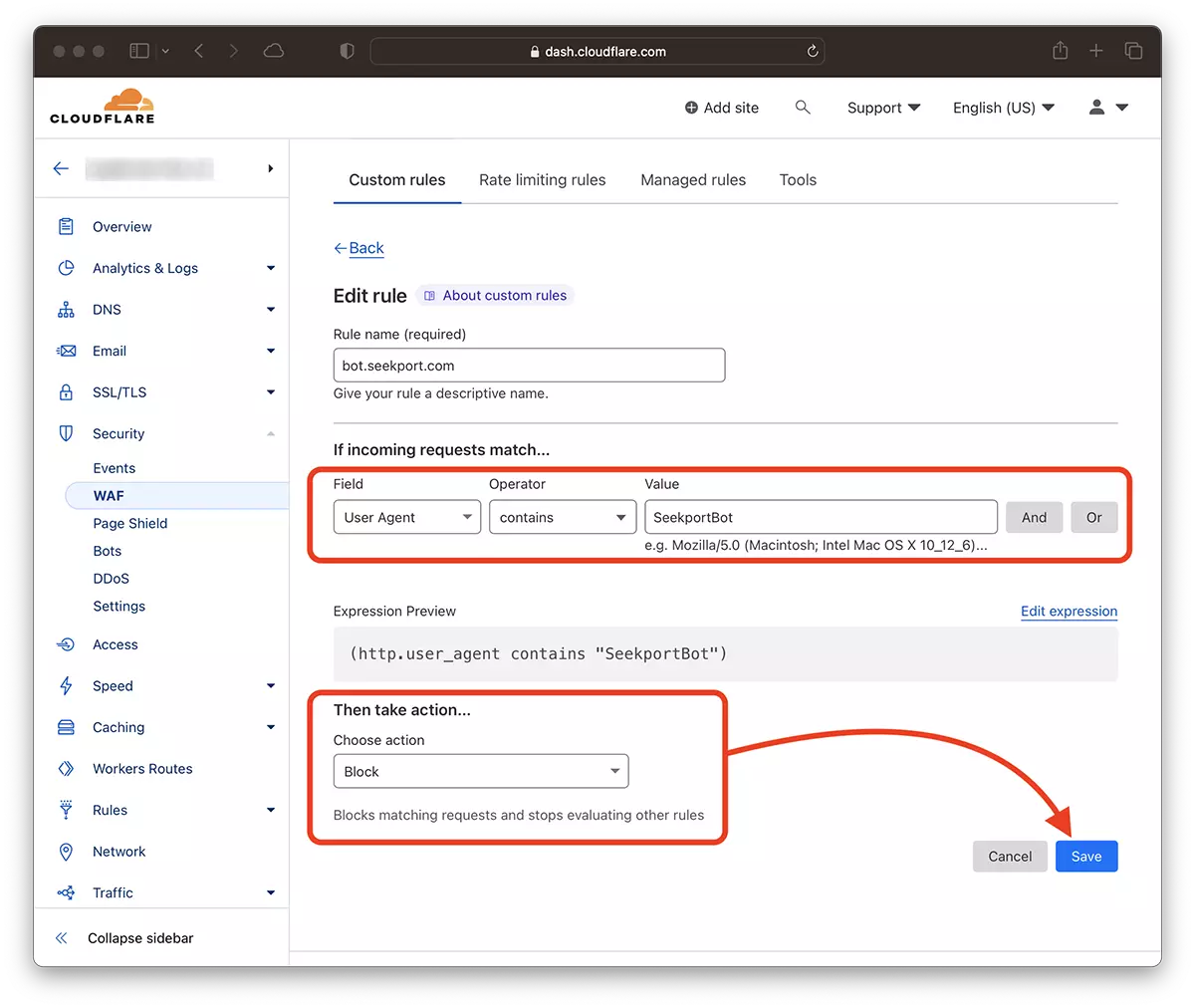
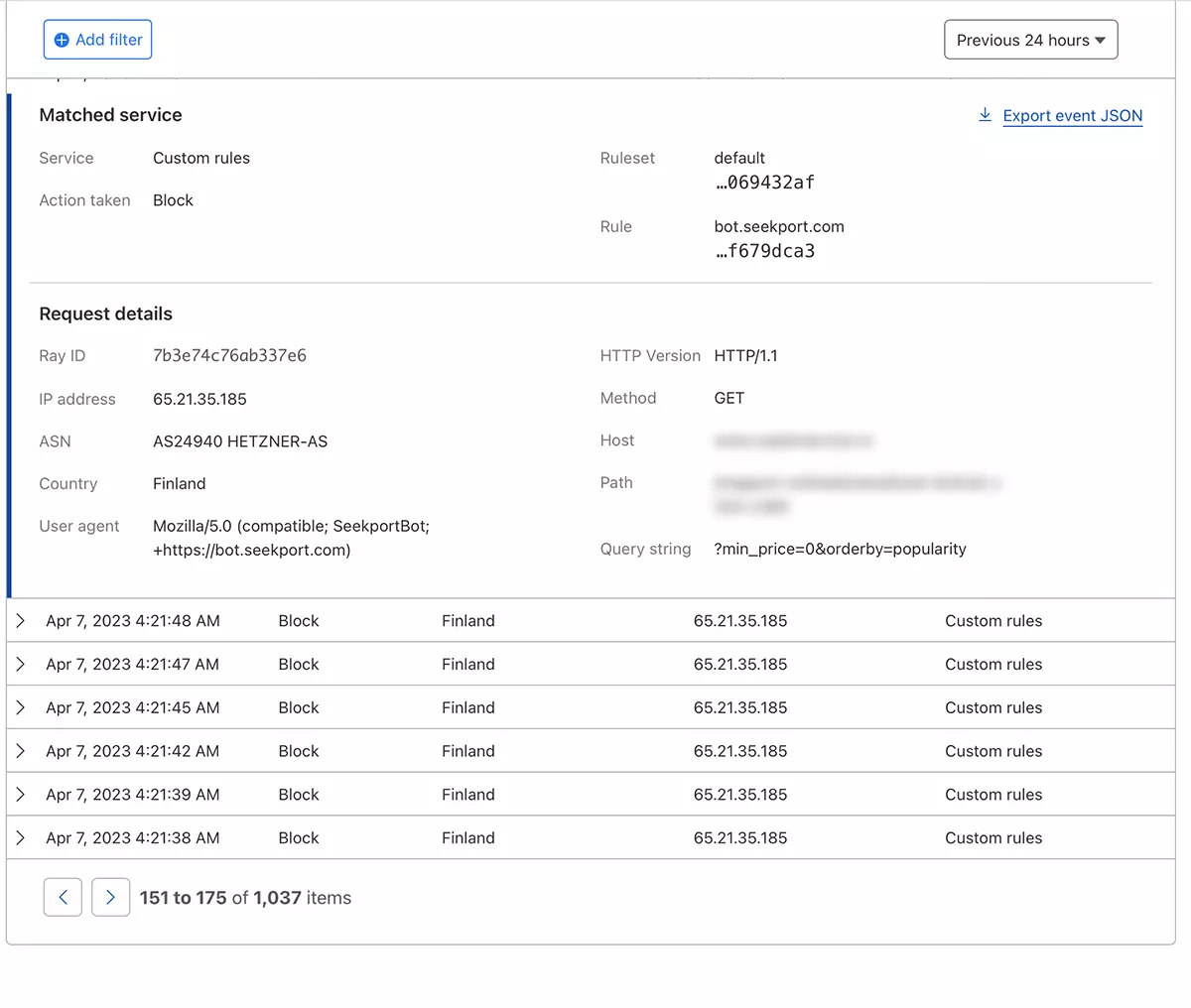
W ciągu zaledwie kilku sekund nowa zasada WAF (Web Application Firewall) Zaczyna robić swój efekt.
Teoretycznie można ustawić częstotliwość, w której można ustawić Spider Web, aby uzyskać dostęp do witryny robots.txt, chociaż… To tylko teoretycznie.
User-agent: SeekportBot
Crawl-delay: 4Wiele robotników internetowych (oprócz Bing i Google) nie przestrzega tych zasad.
Podsumowując, jeśli zidentyfikujesz sieć indeksowania, która nadmiernie uzyskuje dostęp do Twojej witryny, najlepiej zablokować jej całkowity dostęp. Oczywiście, jeśli ten bot nie pochodzi z wyszukiwarki, w której jesteś zainteresowany obecnością.
Może zainteresują Cię także...
