
대부분의 경우 액세스를 차단해야 할 때 SeekportBot 또는 다른 사람에게 crawl bots 웹 사이트에서 그 이유는 간단합니다. 웹 스파이더는 짧은 시간 내에 너무 많은 액세스 권한을 부여하고 서버 웹 리소스를 요청하거나 웹 사이트를 색인화하기를 원하지 않는 검색 엔진에서 비롯됩니다.
콘텐츠
크롤링 봇이 방문한 웹 사이트는 매우 유익합니다. 이 웹 스파이드는 검색 엔진에서 웹 페이지의 내용을 탐색, 처리 및 색인하도록 설계되었습니다. Google과 Bing은 그러한 크롤링 봇을 사용합니다. 그러나 웹 페이지에서 데이터를 수집하기 위해 로봇을 사용하는 검색 엔진도 있습니다. Seekport SeekPortBot Crawler를 사용하여 웹 페이지를 인덱싱하는 이러한 검색 엔진 중 하나입니다. 불행히도, 때로는 과도한 방식으로 사용하고 쓸모없는 트래픽을 수행합니다.
SeekPortBot은 무엇입니까?
SeekportBot 그것은 a입니다 web crawler 회사가 개발했습니다 Seekport독일에 기반을두고 있지만 핀란드를 포함한 여러 국가의 IP를 사용합니다). 이 봇은 검색 엔진의 검색 결과에 표시 할 수 있도록 웹 사이트를 탐색하고 색인하는 데 사용됩니다. Seekport. 내가 아는 한, 비 기능 검색 엔진. 적어도 핵심 문구에 대한 결과를 반환하지 않았습니다.
SeekportBot 사용 user agent:
"Mozilla/5.0 (compatible; SeekportBot; +https://bot.seekport.com)"SeekPortBot 또는 기타 크롤링 봇의 웹 사이트에 대한 액세스를 어떻게 차단합니까?
이 스파이더 웹이나 다른 웹 사이트라는 결론에 도달 한 경우 전체 웹 사이트를 스캔하고 웹 서버를 통해 쓸모없는 트래픽을 만들 필요가 없다면 액세스를 차단할 수있는 몇 가지 방법이 있습니다.
방화벽 서버 웹 레벨
방화벽이 적용됩니다 open-source Linux 운영 체제에 설치할 수 있으며 여러 기준에서 트래픽을 차단하도록 구성 할 수 있습니다. IP 주소, 위치, 포트, 프로토콜 또는 사용자 에이전트.
APF (Advanced Policy Firewall) 서버 수준에서 원치 않는 범프를 차단할 수있는 소프트웨어입니다.
SeekPortBot 및 기타 웹 스파이더는 여러 IP 블록을 사용하기 때문에 가장 효율적인 잠금 규칙은 다음을 기반으로합니다. “user agent“. ASAR, 액세스를 차단하려면 SeekportBot 도움으로 APF, 당신이해야 할 일은 웹 서버에 SSH필터링 규칙을 구성 파일에 추가하십시오.
1. 구성 파일을 엽니 다 nano (또는 다른 편집자).
sudo nano /etc/apf/conf.apf2. 시작하는 줄을 찾으십시오 “IG_TCP_CPORTS” 이 라인의 끝에서 차단하려는 사용자 에이전트를 추가 한 다음 쉼표를 추가하십시오. 예를 들어, 차단하려는 경우 user agent “SeekportBot“, 라인은 다음과 같아야합니다.
IG_TCP_CPORTS="80,443,22" && IG_TCP_CPORTS="$IG_TCP_CPORTS,SeekportBot"3. 파일을 저장하고 APF 서비스를 다시 시작하십시오.
sudo systemctl restart apf.service입장 “SeekportBot” 차단됩니다.
여과법 web crawls CloudFlare의 도움으로 – SeekPortBot 액세스를 차단하십시오
CloudFre의 도움으로 웹 사이트의 일부 비트에 액세스 할 수있는 가장 안전하고 가장 편리한 방법으로 보입니다. 내가 사용한 방법 SeekportBot 온라인 상점으로 트래픽을 필터링합니다.
CloudFlore에 이미 웹 사이트가 추가되었다고 가정하고 DNS 서비스가 활성화되었다고 가정하면 (즉, 사이트로의 트래픽은 클라우드로 수행됩니다) 아래 단계를 따르십시오.
1. Clouflare 계정을 열고 액세스를 제한하려는 웹 사이트로 이동하십시오.
2.로 이동 : Security → WAF 새로운 규칙을 추가하십시오. Create rule.
3. 새 규칙의 이름을 선택하고, Field: User Agent – Operator: Contains – Value: SeekportBot (또는 다른 봇 이름) – Choose action: Block – Deploy.
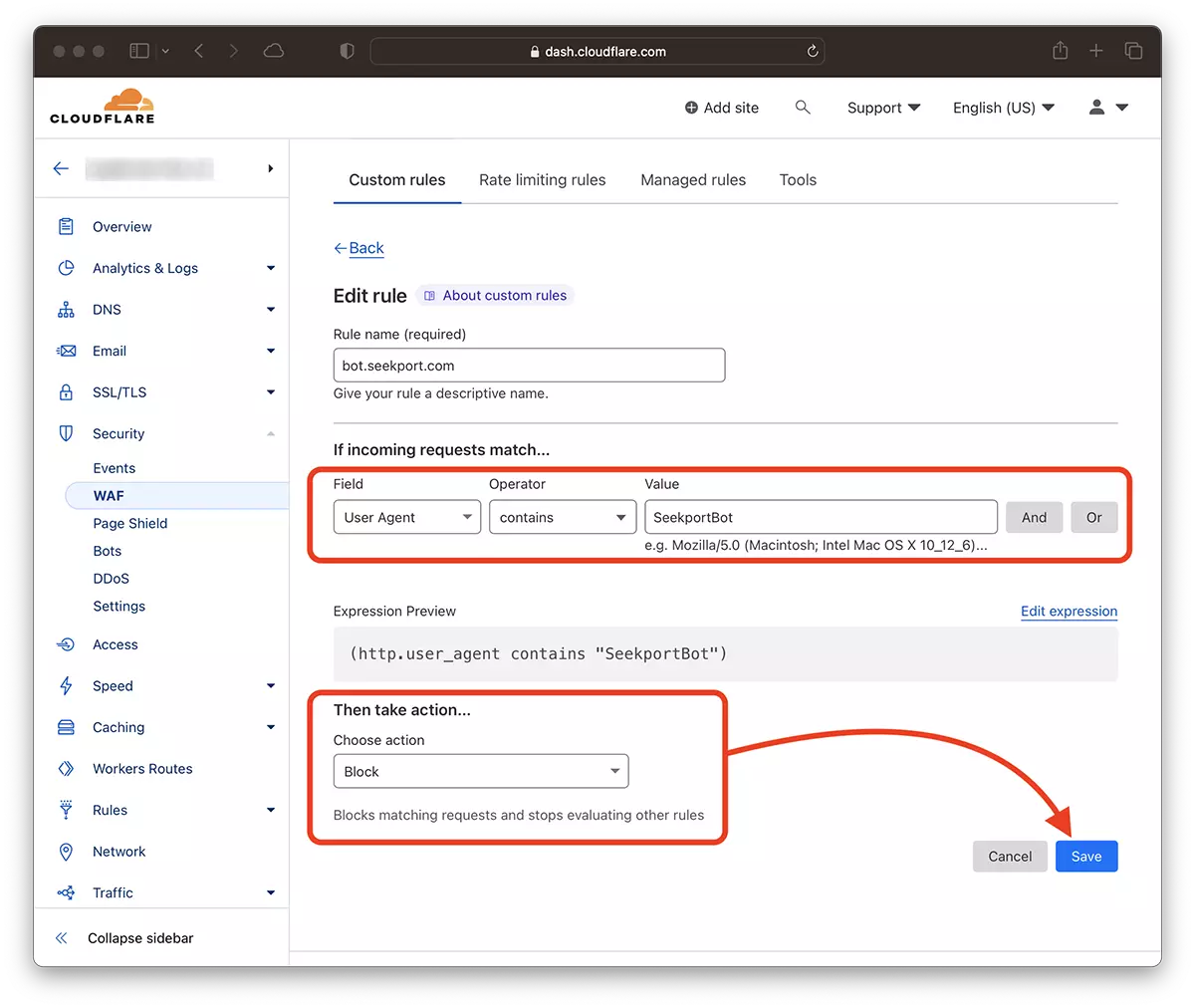
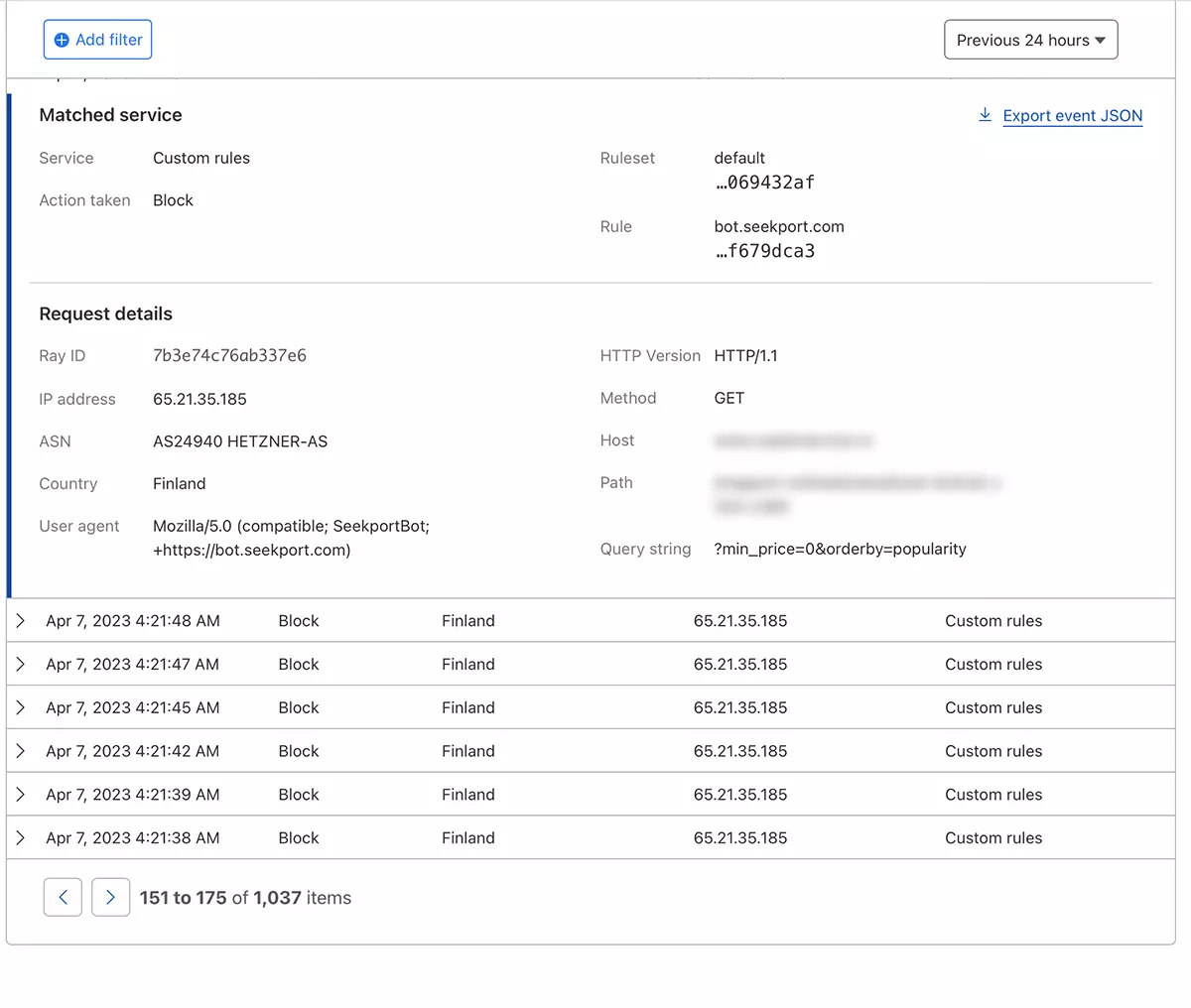
몇 초 만에 새로운 규칙 WAF (Web Application Firewall) 그는 자신의 효과를 내기 시작합니다.
이론적으로, 사이트에 액세스하기위한 거미줄이 설정할 수있는 주파수 robots.txt, 그렇지만… 이론 일뿐입니다.
User-agent: SeekportBot
Crawl-delay: 4많은 웹 크롤러 (Bing 및 Google 외에)는 이러한 규칙을 따르지 않습니다.
결론적으로, 사이트에 과도하게 액세스하는 크롤링 웹을 식별하면 총 액세스를 차단하는 것이 가장 좋습니다. 물론,이 봇이 당신이 존재하는 데 관심이있는 검색 엔진에서 나온 경우.
당신은 또한에 관심이있을 수 있습니다 ...
