
Na maioria das vezes, quando você precisa bloquear o acesso SeekportBot ou outros crawl bots com um site, os motivos são simples. O web spider faz muitos acessos em um curto espaço de tempo e solicita os recursos do servidor web, ou vem de um mecanismo de busca no qual você não deseja que seu site seja indexado.
contente
É muito benéfico para um site visitado por bots de rastreamento. Esses web spiders são projetados para explorar, processar e indexar o conteúdo de páginas da web em motores de busca. Google e Bing usam esses bots de rastreamento. No entanto, também existem motores de busca que utilizam robôs para coletar dados de páginas web. Seekport é um desses motores de busca, que usa o rastreador SeekportBot para indexar páginas da web. Infelizmente, às vezes ele usa excessivamente e cria tráfego desnecessário.
O que é SeekportBot?
SeekportBot É um web crawler desenvolvido pela empresa Seekport, que tem sede na Alemanha (mas utiliza IPs de vários países, incluindo a Finlândia). Este bot é usado para rastrear e indexar sites para que possam ser exibidos nos resultados de pesquisas. Seekport. Um mecanismo de busca não funcional, pelo que sei. Pelo menos, não retornou resultados para nenhuma frase-chave.
SeekportBot USAR user agent:
"Mozilla/5.0 (compatible; SeekportBot; +https://bot.seekport.com)"Como você bloqueia o acesso do SeekePortBot ou de outros rastreamentos para um site
Se você chegou à conclusão de que este web spider ou outro não é necessário verificar todo o seu site e gerar tráfego desnecessário para o servidor web, você tem vários métodos pelos quais pode bloquear o acesso deles.
Firewall em nível de servidor web
Eles são aplicativos de firewall open-source que pode ser instalado em sistemas operacionais Linux e configurado para bloquear o tráfego com base em vários critérios. Endereço IP, localização, portas, protocolos ou agente do usuário.
APF (Advanced Policy Firewall) é um software através do qual você pode bloquear bots indesejados, no nível do servidor.
Como o SeekportBot e outros web spiders usam vários blocos de IPs, a regra de bloqueio mais eficaz é baseada em “user agent“. Então, se você quiser bloquear o acesso SeekportBot com a ajuda APF, tudo que você precisa fazer é conectar-se ao servidor web via SSHe adicione a regra de filtro no arquivo de configuração.
1. Abra o arquivo de configuração com nano (ou outro editor).
sudo nano /etc/apf/conf.apf2. Procure a linha que começa com “IG_TCP_CPORTS” e adicione o agente do usuário que deseja bloquear no final desta linha, seguido de uma vírgula. Por exemplo, se você quiser bloquear user agent “SeekportBot“, a linha deve ficar assim:
IG_TCP_CPORTS="80,443,22" && IG_TCP_CPORTS="$IG_TCP_CPORTS,SeekportBot"3. Salve o arquivo e reinicie o serviço APF.
sudo systemctl restart apf.serviceacesso “SeekportBot” será bloqueado.
Filtração web crawls com a ajuda da Cloudflare – Bloquear o acesso ao SeekportBot
Com a ajuda do Cloudflare, parece-me o método mais seguro e conveniente pelo qual você pode limitar o acesso de alguns bots a um site de várias maneiras. O método que também usei no caso SeekportBot para filtrar o tráfego para uma loja online.
Supondo que você já tenha o site adicionado à Cloudflare e os serviços DNS estejam ativados (ou seja, o tráfego para o site passa pela Cloudflare), siga os passos abaixo:
1. Abra sua conta Clouflare e acesse o site cujo acesso deseja limitar.
2. Vá para: Security → WAF e adicione uma nova regra. Create rule.
3. Escolha um nome para a nova regra, Field: User Agent – Operator: Contains – Value: SeekportBot (ou outro nome de bot) – Choose action: Block – Deploy.
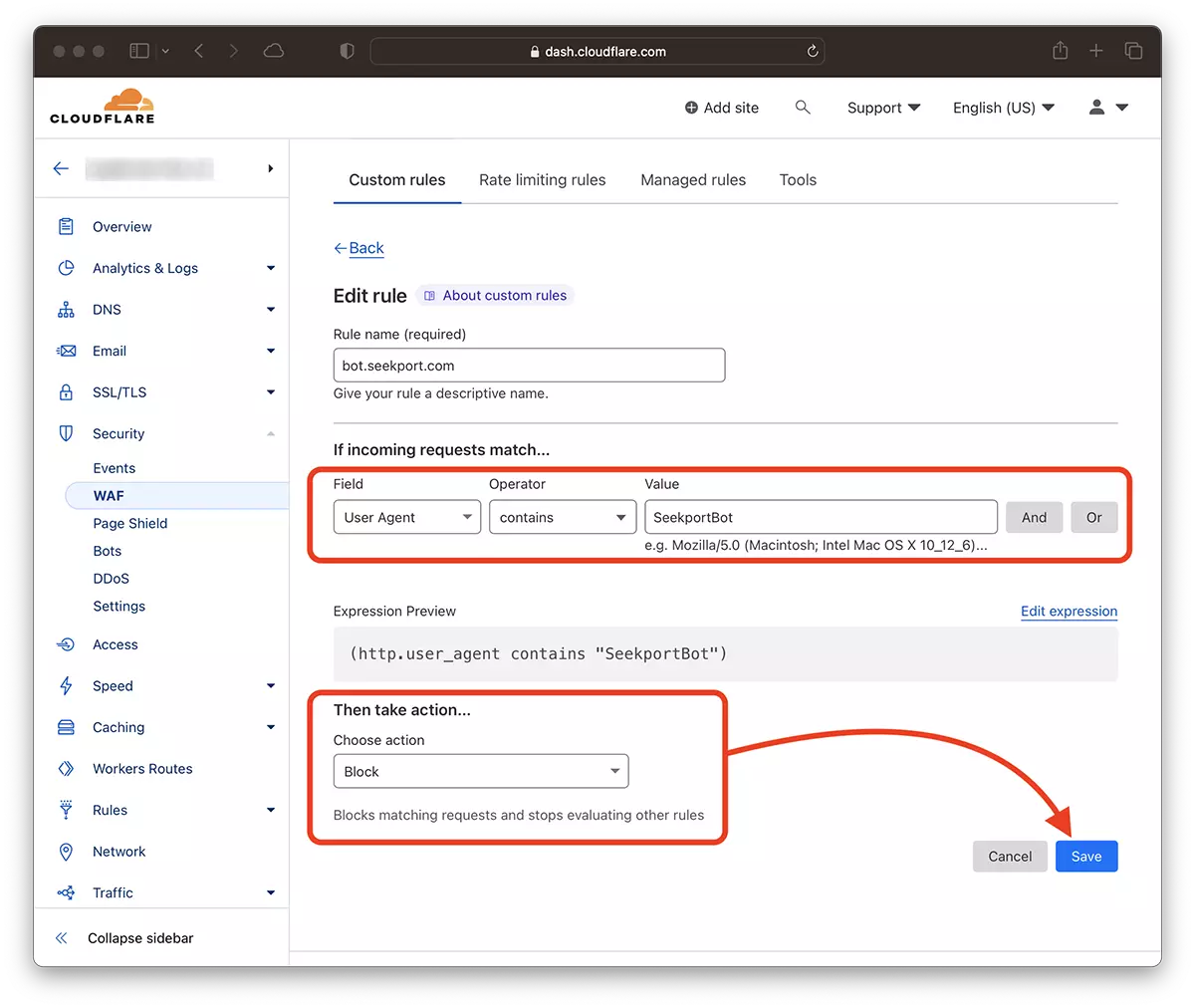
Em apenas alguns segundos, a nova regra WAF (Web Application Firewall) começa a fazer efeito.
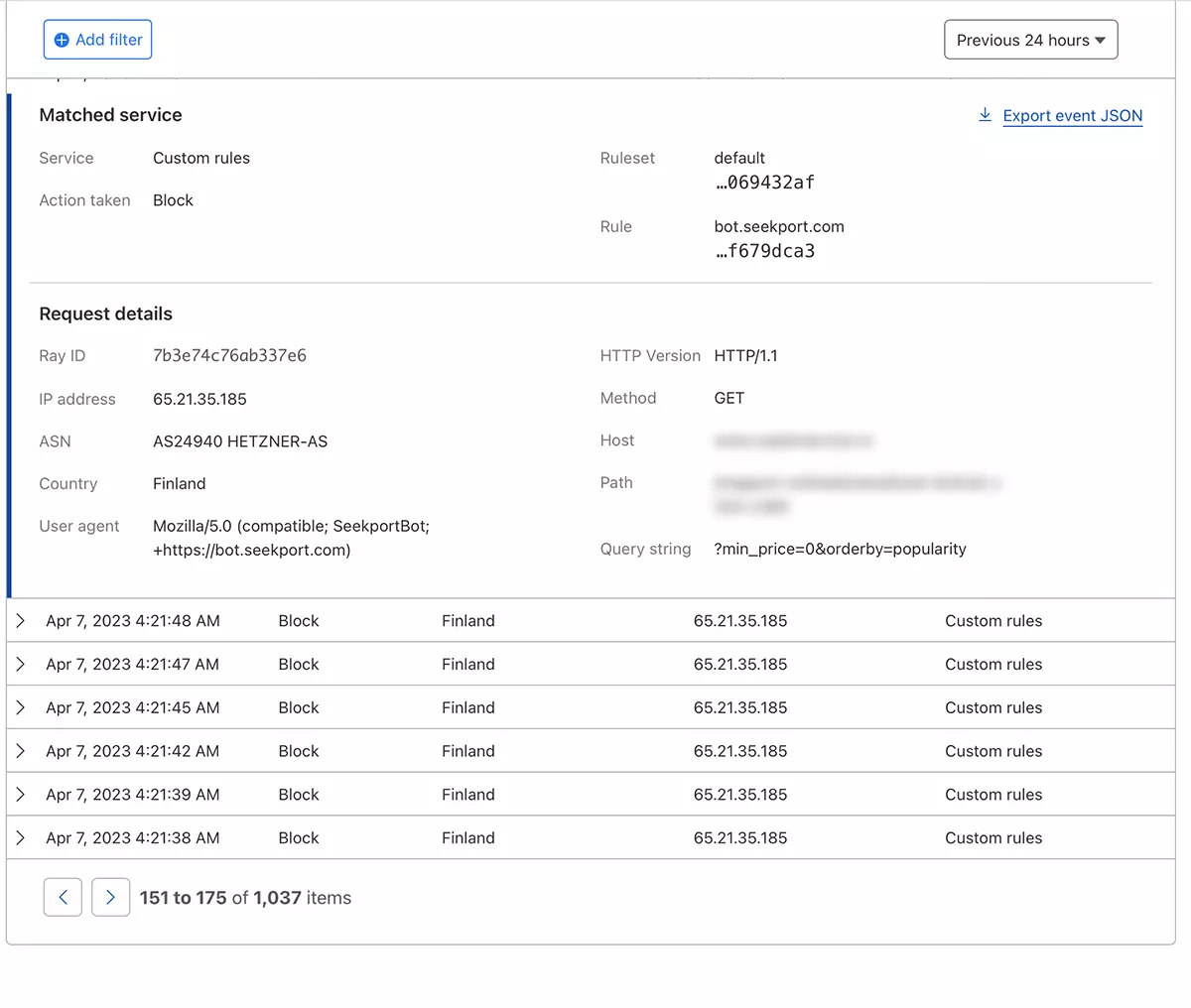
Em teoria, a frequência com que um web spider acessa um site pode ser definida a partir de robots.txt, mas… é apenas em teoria.
User-agent: SeekportBot
Crawl-delay: 4Muitos rastreadores da web (além do Bing e do Google) não respeitam essas regras.
Concluindo, se você identificar um web crawl que acessa excessivamente o seu site, é melhor bloquear seu acesso total. Claro, se este bot não for de um mecanismo de busca no qual você tenha interesse em estar presente.
Você também pode estar interessado em...
